
TLDR: if you have a text input and want to compress the number of tokens fed to your decoder, use a text-based encoder, don’t render an image and use a visual encoder.
Introduction and Context#
Today I was made aware of a recent line of research in Multimodal LLMs that attempts to reduce the number of tokens it takes to represent text. The general approach is to take text, render it as a set of images, then pass it to a multi-modal LLM. The image is parsed by a visual encoder that transforms those images into visual tokens that are then read by the LLM. The advantage of doing this, it is argued, is that the number of visual tokens used to represent the images of the text is less than the number of tokens used to represent the text directly, if you were to use the predominant sub-word tokenizers.
The summary of my argument is that I think rather than transforming text into an image and using a visual encoder to get compressed visual tokens in order to reduce the end number of tokens fed into the decoder, I think it would be more fruitful to train a text-based encoder specifically for compressing text into compressed tokens. In addition, I don’t believe the comparison between visual and textual tokens is ‘fair’ and that it would be more beneficial to evaluate these compression techniques against other related works. Furthermore, I’d also like to discuss the issue of people providing tenuous analogies to the human brain that in actuality aren’t a rigorous explanation of how these models are working, arguing that they shouldn’t be used to drive areas of research to the extent they are.
To be clear, I don’t want to discount the advantages of a visual approach in understanding documents where layout, formatting and diagrams inform the meaning of the document. I’m specifically concerned with the practice of taking existing Unicode text, and transforming it into images in order to reduce the number of tokens used to represent that text.
I’d like to acknowledge that the research I’m talking about is done by people who know far more about Machine Learning than I do, however I still feel that it’s productive to write down my opinion, and in the worst case someone can help me understand why I’m wrong. I’m only a student, but I’d still like to take a stab at offering my thoughts.
Before proceeding any further, I’d like to give a quick primer on LLMs so that those with a less technical background can understand for the purposes of this article what a ‘sub-word tokenizer’ and ‘visual encoder’ are. Some points in this post will remain technical, but hopefully this should help frame the problem.
High level overview of how it works#
How LLMs see text and images#
You might have heard that LLMs predict the next ’token’. A ’token’ is the equivalent of a character in language, it’s the smallest element in a language. However, LLMs when looking
at text don’t see individual characters, instead they normally ‘see’ words or subwords (which just means a part of a word)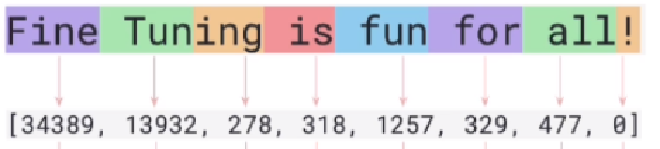
Each of these text tokens is mapped to an embedding, which is a vector that represents that word in a way that the machine can understand.
When we want to make LLMs multi-modal, we need a way of taking things like images and putting it into this format that LLMs understand, a list of tokens (vectors). The traditional way to do that is to have a ‘visual encoder’, which takes as input an image and as output produces a list of tokens (in vector form, the machine language) that represent the image. You can imagine the LLM as a blind man, and the ‘visual encoder’ as a helper, who can describe to him (in machine language) what is happening in the image.
Researchers have found that the number of tokens produced by a visual encoder when looking at an image of text is often less than the number of tokens used if we had gone through each (sub)word and converted each one into a vector. Under the analogy, if the helper was to look at a page in a book and describe the page to the man, this description would be more concise than if the old man were to read it himself (using braille). Part of the reason why is that the helper is doing some sort of mild summarisation of the text (e.g. changing a long wordy sentence to a more quick, to-the-point one), as well as he is speaking in machine language, which is potentially more concise than long winded English. The argument then, by the researchers, is why not stop the blind man reading by himself and instead use the helper to help the blind man read faster or more?
What is compression, and how does it apply here?#
When you take some information, and describe it using a smaller amount of information, we call that ‘compression’. A form of compression that people will often use is a ‘zip’ folder. When I say that machine language is more concise than English in the analogy, what I mean in technical terms is that you might be turning each (sub)word into a vector of let’s say 100 numbers, which is the size of each token. However, there might be cases where you don’t need all 100 numbers to convey the meaning of that subword, meaning some of the numbers are ‘wasted’, or you could use the 100 numbers to express multiple subwords. For example, imagine you have the sentence “mmmm, ok, alright”. If you just go through subword by subword, then you get 100 numbers for ‘mm’, then another 100 for the next ‘mm’, then 100 for ‘,’ etc. However, the visual encoder might look at that sentence and think actually, it can summarise the whole meaning in a single token of 100 numbers. In this way it can potentially convey the exact same sentence, but using fewer numbers (and thus fewer tokens).
The researchers thus compress the text by taking the text, and then turning it into a series of images, passing it through the visual encoder and then passing these visual tokens to the main LLM (which I will sometimes refer to as the decoder). My argument is that instead of taking text, then turning it into an image, then turning that back into some compressed text, why not just directly get the input text and compress it.
Comments on recent papers#
This isn’t a thorough analysis, I’m just going to go through snippets of recent papers on the topic that I have comments on.
DeepSeek-OCR: Contexts Optical Compression#
a crucial research question that current models have not addressed is: for a document containing 1000 words, how many vision tokens are at least needed for decoding?
I think that this is an interesting question, however the question I posit, which I think is more useful, is “for a document containing 1000 words, how many (compressed) text tokens are at least needed for decoding?”.
this approach does not bring any overhead because it can leverage VLM infrastructure, as multimodal systems inherently require an additional vision encoder.
I somewhat disagree to the extent that in order to use visual representations of text instead, then the encoder needs to be trained to take on this larger burden. It may be that a provider would want the visual encoder to be able to represent and compress text perfectly anyway, however their sophisticated architecture that involves being able to dynamically change or control the amount of compression done on the image definitely seems like an extra step.
Overall, though, I think this is a cool paper.
See The Text: From Tokenization to Visual Reading#
Humans read by recognizing words as visual objects, including their shapes, layouts, and patterns, before connecting them to meaning, which enables us to handle typos, distorted fonts, and various scripts effectively.
While this is true to an extent, when I’m writing a prompt to my LLM, all of the meaning needed is in those words, I don’t need it to be considering the shape of each letter. There are definitely fine details of how humans look at words, but for me, when I’m reading, what I’m doing for the most part, or so it feels like, is just connecting words to their meaning. Sure, a visual medium helps handle typos, but I don’t feel like this is a major weakness of existing LLMs that prevents them from functioning well, and I’d argue that an LLM with character-level tokenization should be just as capable of identifying typos as one trained on visual images.
Modern large language models (LLMs), however, rely on subword tokenization, fragmenting text into pieces from a fixed vocabulary. While effective for high-resource languages, this approach over-segments low-resource languages, yielding long, linguistically meaningless sequences and inflating computation
The idea of considering the ‘information-density’ of the specific language or content you’re considering when tokenizing or compressing seems smart, and I don’t disagree that you can have long sequences of text that don’t mean much, but I don’t see how changing that to an even longer list of meaningless pixels helps.
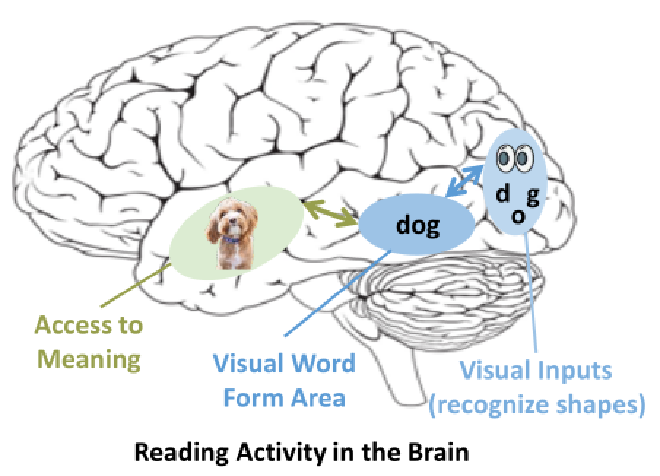
This reminds me of the Hierarchical Reasoning Model paper using mouse brains as inspiration/justification for the architecture. The argument is that the brain follows a pipeline of:
- taking a visual input
- converting that input into a word
- converting that word into meaning
Personally, I’m not against taking inspiration from nature, but I think the comparison to the human brain is a stretch. It also seems strange to me that if we already have the input as a sequence of words (step 2), we would choose to obfuscate the text (turning it into an image) just to follow the full pipeline that humans go through, rather than continuing from the step we’re already on.
Text or Pixels? It Takes Half: On The Token Efficiency Of Visual Text Inputs#
Although vision encoding adds some overhead on smaller models, the shorter decoder sequence yields up to 45% end-to-end speedup on larger ones, demonstrating that off-the-shelf multimodal LLMs can treat images as an implicit compression layer, preserving performance at nearly half the original text-token cost.
My beliefs align more with those presented in this paper. They recognise it’s an off-the-shelf solution that uses existing tools to achieve the goal of compression implicitly, rather than making any sort of special proclamations about the properties of human vision to justify the use of a visual representation outside of allowing us to use existing encoders integrated with LLMs.
bonus: Andrej Karpathy tweet#
Andrej Karpathy also tweeted about the deepseek OCR paper:
I quite like the new DeepSeek-OCR paper. It’s a good OCR model (maybe a bit worse than dots), and yes data collection etc., but anyway it doesn’t matter.
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
Maybe it makes more sense that all inputs to LLMs should only ever be images. Even if you happen to have pure text input, maybe you’d prefer to render it and then feed that in: - more information compression (see paper) => shorter context windows, more efficiency - significantly more general information stream => not just text, but e.g. bold text, colored text, arbitrary images. - input can now be processed with bidirectional attention easily and as default, not autoregressive attention - a lot more powerful. - delete the tokenizer (at the input)!! I already ranted about how much I dislike the tokenizer. Tokenizers are ugly, separate, not end-to-end stage. It “imports” all the ugliness of Unicode, byte encodings, it inherits a lot of historical baggage, security/jailbreak risk (e.g. continuation bytes). It makes two characters that look identical to the eye look as two completely different tokens internally in the network. A smiling emoji looks like a weird token, not an… actual smiling face, pixels and all, and all the transfer learning that brings along. The tokenizer must go.
OCR is just one of many useful vision -> text tasks. And text -> text tasks can be made to be vision ->text tasks. Not vice versa.
So many the User message is images, but the decoder (the Assistant response) remains text. It’s a lot less obvious how to output pixels realistically… or if you’d want to.
Now I have to also fight the urge to side quest an image-input-only version of nanochat…
My quick thoughts:
- If you wanted to use bidirectional attention then why not train a bidirectional encoder on the text directly? The use of bidirectional attention and text representations are orthogonal.
- I agree that a sub-word tokenizer is ugly, but I’m not convinced rendering text as an image, turning it into patches, computing attention between those, and outputting some compressed visual tokens is any less ugly. You’re essentially just swapping a linguistic tokenizer that deals in subwords for visual one that deals in patches.
Main Arguments#
pixel-based representations of text are worse#
Turning text into an image fundamentally goes against common machine learning sense; you are going from a ‘decent’ abstract representation (e.g. index of a word or half of a word) to a bad one with lots of redundancy. The font or position of text in an image is not relevant to the meaning of it, so it doesn’t make sense to add ’noise’ to your input before compressing it.
Let’s say you are doing a deepseek-esque experiment where you have a block of text, and you want to use some form of compression to make the minimum number of tokens (of a set dimensionality) such that the original text can be recovered from the input (and thus you can conclude that your method of compression doesn’t lose too much of the original information). If you are first projecting the text to a visual representation and then feeding that to a visual encoder, and you get the original text at the end, then you can conclude either:
- the token representation contains the minimal amount of information needed to represent the text, in which case no visual information is conserved
- the token representation also contains some amount of visual information
In case 1, none of the visual information is being conserved, so there is no gain from transforming the text into an image. In case 2, the tokens contain some amount of ’extra’ information, meaning the input hasn’t been compressed as much as possible.
Over-eagerness to make analogies to biological brains#
Criticising anthropomorphism in AI in 2025 definitely feels like beating a dead horse, however I want to focus specifically on making analogies or drawing inspiration from animal brains when doing academic research. While this is an obvious and potentially good source of inspiration, it can often come across as somewhat hand-wavy, where the author selects a very specific feature of the way a brain works, and uses that to justify an architectural decision, despite the fact that this feature obviously operates in a very different context: the brain works very differently to an artificial neural network. The most recent example of this, which is why it’s on my mind, is the Hierarchical Reasoning Model paper, which was quickly followed by the Tiny Recursive Model paper in response, which criticises the prior paper for not thoroughly justifying their architectural decisions and demonstrates how their explanation based on the brains of mice can be done away with in favour of a simpler explanation involving the use of a scratchpad.
Today in my lecture for Nature-Inspired Computing, we were discussing the paper “Metaheuristics - The Metaphor Exposed” in which the author criticises the over-use of metaphors and analogies to nature within the field of metaheuristics, saying that it makes it harder for a technical audience to understand the algorithms being employed.
For a few decades, every year has seen the publication of several papers claiming to present a “novel” method for optimization, based on a metaphor of a process that is often seemingly completely unrelated to optimization. The jumps of frogs, the refraction of light, the flowing of water to the sea, an orchestra playing, sperm cells moving to fertilize an egg, the spiraling movements of galaxies, the colonizing behavior of empires, the behavior of bats, birds, ants, bees, flies, and virtually every other species of insects – it seems that there is not a single natural or man-made process that cannot be used as a metaphor for yet another “novel” optimization method
Now I don’t think that AI research suffers from this problem to the same extent as the field of metaheuristics as portrayed in this paper, in particular the issue he highlights where technical terms like “population” are renamed to “harmony memory” and “sample” is changed to “note”, however I do think both can potentially suffer from an over-reliance on nature to explain why an algorithm works. In metaheuristics, when you justify why an algorithm works using a line like ’this is analogous to how bats use echolocation to navigate a cave’ instead of ‘it uses this specific way of doing local search which improves exploration’, it makes the algorithm mysterious: it works because nature does it, and nature is right. Similarly, the brain can offer inspiration for ideas in AI, but when part of your justification for an architecture decision is ’this is analogous to how the brain does it’, then it makes the algorithm harder to understand or build upon.
I believe that within the broader field of ML and AI, research on LLMs is particularly susceptible to this line of thinking. The argument presented in the ‘See the Text’ paper that an LLM would somehow learn better if trained on images rather than text because that’s how humans interpret the world seems to place LLMs on a pedestal of anthropomorphism that other Machine Learning models aren’t given. For example, if you were trying to predict house prices using the California House Price dataset, would you first convert the number of rooms into an image of the number before feeding it to the model? Of course not. Just because LLMs seem more “human-like” doesn’t necessarily mean that a good representation or architectural feature in a human brain would also be good for an artificial neural network.
vision isn’t even how humans understand language (fundamentally)#
In the case of emojis, we understand them visually in that the character’s appearance is tied to its meaning, but this isn’t generally the case for text; the shape of the letters in ‘cat’ doesn’t enhance or help my understanding of what the word means much. I could look at a word in Arabic and make simple guesses about the meaning based on the appearance, such as “this word is really long, so it is less likely to be a very common word”, but I couldn’t get close to telling you the meaning of a sentence just by looking at the shape of it.
I should note that there are pictorial languages, for example Mandarin, but even these are very abstract and it is difficult to look at a character and say ‘ah, that must mean cat’.
Fundamentally, I think at least for me I understand language more like how an LLM views it: each word is (sort of) its own unique object in my brain, ‘mat’ and ’nat’ are both just a combination of letters that point to a different part in my brain. Of course, things like the layout of a document can change how you view text, but this research simply proposes taking a block of text as Unicode and then rendering it as a block of text in an image.
Interestingly, as an aside, if you are interested in a visual representation then I think you could also make the case for a verbal representation of language, because how a language sounds has evolved over a long period of time to convey some sort of meaning. Again, you can’t understand what another person is saying just from the sound of the word, but at least to English speakers there are definitely patterns that inform how we understand words, like “lots of consonants makes a word sound harsher”.
Why the comparison between visual and text tokens isn’t fair#
The ‘See the Text’ paper says:
SEETOK first renders text into images and leverages the visual encoders of pretrained MLLMs (e.g., Qwen2.5-VL) to extract textual representations, which are then passed to the LLM backbone for deeper processing.
I believe that in some cases when people are discussing the compression of text using these methods they directly compare visual tokens and text tokens as if both are just “textual representations”, or two different ways of representing the same thing (e.g. a single word in isolation). In actuality, they are very different. In the case of the visual tokens they have already been pre-processed, including using local and global attention with reference to other parts of the image, so the tokens are both more compressed and conceptually ‘richer’. Therefore, in some sense it isn’t ‘fair’ to measure how many visual tokens it takes with this preprocessing stage to the number of text tokens it takes without any such processing. Of course it is useful to look at the amount of compression achieved, but not one of the papers provides a comparison of their method against other methods to compress the context.
Why we should consider adding the text encoder back (in some form)#
Originally the transformer architecture used both an encoder and a decoder, however LLM architectures subsequently moved to becoming decoder only due to the significant speed-up in training when just using masked self-attention. However, I believe that this work on visual encoders as compression tools highlights the possibility of their return, in some form. In the original conception of the transformer, the architecture used a similarly sized encoder as decoder which in turn meant that the slowdown from training the encoder was very significant. However, the work highlighted here shows that you can take a relatively small encoder and large decoder and use the encoder to do some compression of the input, which then gives large computational savings due to the reduced number of tokens in the context of the decoder.
Therefore, while the encoder might originally have been a barrier to efficient training, it could potentially be used in the future as an opportunity to increase the efficiency of the decoder, where the majority of computational resources are now spent.
Conclusion#
Using a visual encoder to compress text, while a novel idea, ultimately feels to me more of a clever workaround that utilises existing tools than an elegant long term solution. The root problem isn’t that text is an unsuitable input, it’s that current subword tokenizers are inefficient. The best way to address the problem is to directly attend to the text-processing pipeline itself. To put it simply, I think the best way to compress text is to use an encoder trained on compressing text. This is why I think that the return of a small dedicated text encoder, designed specifically to compress text tokens for a large decoder, is a more promising avenue for future research.
Right now I don’t have the time or the resources to go about training an encoder (and a decoder trained to use it), so I shall leave this rant here and hopefully in a few months someone will put out a paper doing this in a way that achieves better compression than the visual encoding approach and I can say “I told you so”.